4.2
Souhrnné charakteristiky
Tabulky rozdělení četností nám bezpochyby pomohou při získávání přehledu o statistickém souboru, ovšem jejich využití např. při porovnávání více souborů mezi sebou není tím nejlepším možným řešením. K tomu, abychom zkoumaný soubor popsali a shrnuli informaci, která je obsažená ve zjištěných statistických údajích, používáme tzv. souhrnné charakteristiky. „Souhrnné charakteristiky v sobě obsahují koncentrovanou informaci o statistické proměnné z různých hledisek.“ [3] Jde o to, aby těchto charakteristik nebylo příliš mnoho a zároveň, aby dostatečně přesně popisovaly vlastnosti zkoumaného souboru.
Předtím, než si popíšeme, jaké známe souhrnné charakteristiky, je vhodné zmínit rozdíl mezi charakteristikami prostými a váženými.
Definice
„Charakteristiky prosté se používají v případě, že hodnoty proměnné nejsou vyjádřeny pomocí tabulky četností, tj. všechny varianty hodnot jsou uvedeny tolikrát, kolikrát se v daném souboru vyskytují… Charakteristiky vážené se používají v případě, že jsou hodnoty proměnné vyjádřeny pomocí tabulky četností.“ [3]
Poznámka
Ovšem je nutné si uvědomit, že pokud se jedná o stejné vstupní hodnoty zadané jednou v prostém a podruhé ve váženém tvaru, pak zkoumaná charakteristika nabývá stejného výsledku, ať už je použit postup výpočtu v prosté nebo vážené formě.
Schéma členění souhrnných charakteristik je zobrazeno na následujícím obrázku 4. Dále v textu bude toto třídění podrobněji popsáno.
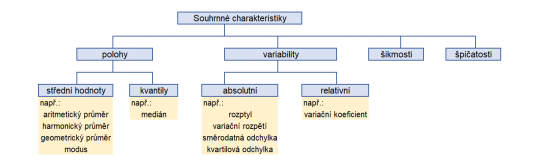
Obr. 4. Schéma členění souhrnných charakteristik
4.2.1
Charakteristiky polohy
Charakteristiky polohy nebo také míry úrovně, jak už z jejich označení vyplývá, popisují statistický soubor z hlediska úrovně (velikosti) proměnných. Jak již bylo uvedeno ve schématu 4, dále se dělí tyto charakteristiky na střední hodnoty a kvantily. Jejich podrobnější popis včetně vzorových příkladů bude uveden dále. Charakteristiky úrovně je možné počítat zejména pro kvantitativní typ proměnných.
ARITMETICKÝ PRŮMĚR
Definice
Aritmetický průměr je součet všech hodnot vydělený jejich počtem.
Aritmetický průměr je zřejmě nejznámějším a nejčastěji používaným typem průměru a najde své využití při řešení většiny statistických úloh. Aritmetický průměr lze snadno vypočítat a interpretovat, ale je náchylný na extrémní, odlehlé hodnoty.
Prostý aritmetický průměr je možné vypočítat podle následujícího vzorce
,
kde x1, x2, …, xn jsou zjištěné neuspořádané hodnoty o celkovém počtu n.
Výpočet prostého aritmetického průměru tedy používáme v případě, že vstupní hodnoty nejsou uspořádány do tabulky četností.
Příklad
Příklad – prostý aritmetický průměr
V továrně zabývající se výrobou horských kol pracuje 12 zaměstnanců. Máme k dispozici údaje o počtu vyrobených kol každým zaměstnancem během jedné pracovní směny: 5, 6, 9, 4, 6, 7, 5, 7, 6, 8, 7, 5. Pomocí vzorce
vypočítejte průměrný počet kol vyrobených za jednu pracovní směnu.
Zobrazit řešení
Skrýt řešení
Řešení
Průměrný počet vyrobených horských kol během jedné pracovní směny jedním zaměstnancem je 6,25.
Pokud zjištěné hodnoty zkoumaného statistického souboru uspořádáme do tabulky četností, používáme pro výpočet aritmetického průměru jeho vážený tvar.
Vážený aritmetický průměr můžeme zapsat v tomto tvaru:
.
Četnosti, které zde značíme n1, n2, …, nk, představují váhu jednotlivých obměn proměnných x1, x2, …, xk. Jinak řečeno, váhy nám ukazují, jak jsou jednotlivé kategorie výsledků důležité z pohledu jejich zastoupení v souboru.
Ovšem četnosti, které zde zastupují váhu jednotlivých obměn zkoumané statistické proměnné, mohou být také zapsány v relativním vyjádření:
.
Poznámka
Jestliže počítáme vážený aritmetický průměr z intervalového rozdělení, pak se do vzorce pro jeho výpočet namísto xi dosazuje prostřední hodnota intervalu (značíme
).
Příklad
Příklad – vážený aritmetický průměr
Údaje z předchozího příkladu na výpočet aritmetického průměru v prostém tvaru využijeme i zde, ale vše uspořádáme do tabulky četností. V továrně zabývající se výrobou horských kol pracuje 12 zaměstnanců. Máme k dispozici údaje o počtu vyrobených kol každým zaměstnancem během jedné pracovní směny: 5, 6, 9, 4, 6, 7, 5, 7, 6, 8, 7, 5. Pomocí vzorce
vypočítejte průměrný počet kol vyrobených za jednu pracovní směnu.
Zobrazit řešení
Skrýt řešení
Řešení
Počet vyrobených kol xi | Počet zaměstnanců ni | |
4 | 1 | 4 |
5 | 3 | 15 |
6 | 3 | 18 |
7 | 3 | 21 |
8 | 1 | 8 |
9 | 1 | 9 |
celkem | 12 | 75 |
Stejně jako v předchozím příkladu je průměrný počet vyrobených horských kol během jedné pracovní směny jedním zaměstnancem roven 6,25.
Stále zde totiž platí, že pokud se jedná o stejné vstupní hodnoty zadané jednou v prostém a podruhé ve váženém tvaru, pak zkoumaná charakteristika nabývá stejného výsledku, ať už je použit postup výpočtu v prosté nebo vážené formě.
Další příklady k procvičení najdete v kapitole Kontrolní otázky a příklady.
Aritmetický průměr má také velice zajímavé a užitečné vlastnosti. Některé tyto vlastnosti můžeme vhodně využít při výpočtech.
Vlastnosti aritmetického průměru
- Součet odchylek hodnot proměnné od jejího aritmetického průměru je vždy nulový: .
- Aritmetický průměr konstanty je konstanta: .
- Přičteme-li k jednotlivým hodnotám proměnné nenulovou konstantu k, zvýší se o tuto konstantu i aritmetický průměr: .
- Násobíme-li jednotlivé hodnoty proměnné nenulovou konstantou k, je touto konstantou násoben i průměr: .
- Násobíme-li váhy (ni nebo pi) aritmetického průměru nenulovou konstantou k, průměr se nezmění.
- Aritmetický průměr součtu nebo rozdílu hodnot dvou proměnných je roven součtu nebo rozdílu aritmetických průměrů těchto proměnných: .
- Je-li statistický soubor rozdělen do m dílčích podsouborů, v nichž známe jednotlivé dílčí průměry a počty pozorování n1, n2, …, nm, resp. p1, p2, …, pm, pak průměr celého souboru je váženým aritmetickým průměrem těchto dílčích průměrů, kde vahami jsou četnosti podsouborů: , resp. .
Poznámka
„Vztahu o dílčích průměrech lze rovněž využít k výpočtu aritmetického průměru z intervalového rozdělení četností v případě, že neznáme průměry v jednotlivých skupinách.“ [1]
Příklad
Příklad – vlastnosti aritmetického průměru 1
Na tomto příkladu si procvičíte využití vlastností aritmetického průměru. Pro názornost jsou zde uvedeny i vstupní hodnoty xi, ovšem, jak sami zjistíte, díky platnosti vlastností aritmetického průměru tyto informace nejsou pro výpočet nového průměru potřebné.
V tabulce jsou uvedeny platy 5 zaměstnanců, v průměru pobírají plat 26 060,- Kč.
Zaměstnanec i | Plat xi |
1 | 18 600 |
2 | 28 700 |
3 | 34 400 |
4 | 21 900 |
5 | 26 700 |
celkem | 130 300 |
Vaším úkolem je vypočítat, jak se změní průměrný plat zaměstnanců, jestliže:
- každý pracovník dostane přidáno 1 000 Kč,
- každý pracovník dostane 1,5násobek platu,
- každý pracovník dostane přidáno 5 % ze stávajícího platu.
Zobrazit řešení
Skrýt řešení
Řešení
Jak již bylo uvedeno dříve, vstupní hodnoty o platech zaměstnanců nejsou pro výpočet nového průměru zapotřebí. Postačí nám původní hodnoty aritmetického průměru a znalost jeho obecných vlastností.
- každý pracovník dostane přidáno 1 000 Kč
Tato úprava se týká třetí vlastnosti aritmetického průměru, která hovoří o přičítání nenulové konstanty
.
Stačí tedy vzít původní hodnotu průměrného platu zaměstnanců, přičíst 1 000 a máme nový průměrný plat.
Ti, kdo nevěří, mohou si ke každé původní hodnotě platu, uvedeným v tabulce v zadání, přičíst 1 000, všechny tyto nové hodnoty sečíst, vydělit celkovým počtem (5) a získají také tuto novou hodnotu průměrného platu.
- každý pracovník dostane 1,5násobek platu
Tato úprava se týká čtvrté vlastnosti aritmetického průměru, která hovoří o násobení nenulovou konstantou
.
Stačí tedy vzít původní hodnotu průměrného platu zaměstnanců, vynásobit 1,5× a získáme hodnotu nového průměrného platu.
Opět ti, kdo nevěří, mohou si každou původní hodnotu platu, vynásobit 1,5×, všechny tyto nové hodnoty sečíst, vydělit celkovým počtem (5) a získají také tuto novou hodnotu průměrného platu.
- každý pracovník dostane přidáno 5 % ze stávajícího platu
Tato úprava se týká také čtvrté vlastnosti aritmetického průměru, která hovoří o násobení nenulovou konstantou
.
Vezmeme původní hodnotu průměrného platu zaměstnanců, vynásobíme ji hodnotou 1,05 (nárůst na 105 % původní hodnoty) a získáme hodnotu nového průměrného platu.
Opět ti, kdo nevěří, mohou si každou původní hodnotu platu, vynásobit 1,05×, všechny tyto nové hodnoty sečíst, vydělit celkovým počtem (5) a získají také tuto novou hodnotu průměrného platu.
Příklad
Příklad – vlastnosti aritmetického průměru 2
Máme dvě skupiny osob, muže a ženy. Průměrná hmotnost žen je 65 kg a průměrná hmotnost mužů je 80 kg. Obě skupiny byly sloučeny do jednoho velkého souboru. Jaká bude průměrná hmotnost celého souboru (mužů a žen dohromady), jestliže:
- žen je 60 a mužů 40,
- žen je 35 a mužů 35,
- ženy mají relativní četnost 0,3 a muži 0,7?
Zobrazit řešení
Skrýt řešení
Řešení
Na tomto příkladu si procvičíte znalost sedmé vlastnosti aritmetického průměru uvedenou výše.
- žen je 60 a mužů 40
Za ni dosazujeme počty mužů a žen a za
jejich dílčí průměrné hmotnosti.
Průměrná hmotnost všech osob dohromady je 71 kg.
- žen je 35 a mužů 35
Toto zadání je trochu chyták. Jsou zde sice uvedeny četnosti (váhy) dvou skupin osob, ale tyto četnosti jsou shodné. Takže výsledek je stejný, jako kdybychom udělali obyčejný aritmetický průměr dvou hodnot (65 a 80) bez vážení.
Průměrná hmotnost všech osob dohromady je 72,5 kg.
- ženy mají relativní četnost 0,3 a muži 0,7
Při tomto zadání je třeba použít vzorec s relativními četnostmi:
Průměrná hmotnost všech osob dohromady je 75,5 kg.
Další příklady k procvičení vlastností aritmetického průměru najdete v kapitole Kontrolní otázky a příklady.
HARMONICKÝ PRŮMĚR
Definice
Harmonický průměr je podíl počtu pozorování a součtu převrácených hodnot proměnné.
Harmonický průměr využijeme tam, kde mají smysl převrácené hodnoty. Pro jeho výpočet používáme pouze kladné hodnoty. „Praktické použití harmonického průměru je například při výpočtu průměrné rychlosti, průměrné délky potřebné ke splnění určitého úkonu, pokud se plní dané úkony současně atd.“ [3]
Prostý harmonický průměr je možné vypočítat podle následujícího vzorce
,
kde x1, x2, …, xn jsou zjištěné neuspořádané kladné hodnoty o celkovém počtu n.
Výpočet prostého harmonického průměru tedy používáme v případě, že vstupní hodnoty nejsou uspořádány do tabulky četností.
+
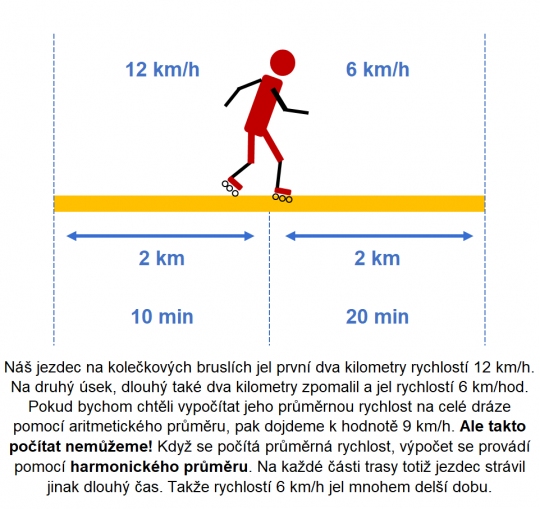
Obr. 5. Využití harmonického průměru při výpočtu průměrné rychlosti
Příklad
Příklad – prostý harmonický průměr
Řidič jel z Jičína do Liberce rychlostí 80 km/h a z Liberce do Jičína rychlostí 105 km/h.
Vypočítejte průměrnou rychlost řidiče na celé trase, tj. z Jičína do Liberce a zpět, pokud víme, že jel stejnou trasou.
Zobrazit řešení
Skrýt řešení
Řešení
Pro výpočet použijeme vzorec na prostý harmonický průměr
Řidič jel na trase z Jičína do Liberce a zpět průměrnou rychlostí 90,8 km/hod.
Pokud zjištěné hodnoty zkoumaného statistického souboru uspořádáme do tabulky četností, používáme pro výpočet harmonického průměru jeho vážený tvar.
Vážený harmonický průměr můžeme zapsat v tomto tvaru:
.
Četnosti, které zde značíme n1, n2, …, nk, představují váhu jednotlivých obměn proměnné x1, x2, …, xk.
Pokud jsou četnosti (váhy) zapsány v relativním vyjádření, pak má výraz následující podobu:
.
Poznámka
„Praktické používání harmonického průměru ve statistické praxi je vcelku omezené. V části pojednávající o teorii indexů se s ním setkáváme při výpočtu průměrových tvarů souhrnných indexů.“ [1]
GEOMETRICKÝ PRŮMĚR
Definice
Geometrický průměr je definován jako n-tá odmocnina ze součinu n kladných hodnot.
Geometrický průměr ve statistice využijeme nejčastěji k výpočtu průměrného koeficientu růstu. Pro výpočet geometrického průměru používáme pouze kladné hodnoty.
Prostý geometrický průměr je možné vypočítat podle následujícího vzorce
,
kde x1, x2, …, xn jsou zjištěné neuspořádané kladné hodnoty o celkovém počtu n.
Vážený geometrický průměr můžeme zapsat v tomto tvaru:
.
Četnosti, které zde značíme n1, n2, …, nk, představují váhu jednotlivých obměn proměnné x1, x2, …, xk.
Poznámka
Pokud bychom všechny výše uvedené průměry spočítali na základě stejných hodnot, pak by mezi nimi platil tento vztah
.
MODUS
Definice
Modus je definován jako nejčastěji se vyskytující kategorie sledované proměnné ve vztahu k nejbližšímu okolí.
Modus budeme značit symbolem
. „Existují i rozdělení četností, které mají více než jednu modální hodnotu a nazývají se vícemodální. K této skupině patří i rozdělení četností s dvěma mody, a to označujeme jako bimodální rozdělení četností.“ [3] Více informací o tvarech rozdělení, se kterými se pojí i počet a umístění modu v rozdělení četností, je uvedeno v kapitole 4.3.
KVANTILY
Definice
P-procentní kvantil je hodnota, která rozděluje uspořádaný soubor hodnot určité statistické proměnné na dvě části – jedna obsahuje ty hodnoty, které jsou menší nebo rovny p-procentnímu kvantilu, druhá část obsahuje hodnoty, které jsou větší nebo rovny p-procentnímu kvantilu.
Kvantily budeme značit symbolem
, kde za dolní index p vždy doplníme konkrétní hodnotu p-procentního kvantilu, se kterým zrovna pracujeme.
Jestliže chceme určit hodnotu p-procentního kvantilu, je nutné nejprve uspořádat soubor hodnot podle velikosti od nejnižší hodnoty po nejvyšší a poté je možné určit pořadí jednotky zp, jejíž hodnota je p-procentní kvantil. Nalezení pořadí jednotky zp provedeme za pomocí tohoto výrazu:
,
kde za p dosazujeme hledaný kvantil (procento), n označuje rozsah souboru a zp je pořadové číslo jednotky, jejíž hodnota je hledaný kvantil, nebo číslo mezi dvěma pořadími. Jestliže se pořadové číslo nachází mezi dvěma pořadími, pomůžeme si zpravidla aritmetickým průměrem těchto dvou hodnot, abychom získali jednu hodnotu pro p-procentní kvantil.
Některé kvantily mají svoje označení. Můžeme se tak setkat s kvartily, které dělí soubor na čtvrtiny (25% kvantil, 50% kvantil, 75% kvantil). U kvartilů se můžeme také setkat s následujícím označením:
- dolní kvartil , který odděluje čtvrtinu nejnižších hodnot,
- prostřední kvartil , nebo také medián , který rozděluje soubor na dvě stejné části a
- horní kvartil , který odděluje ¾ nejnižších hodnot proměnné od ¼ nejvyšších.
Medián patří mezi často používané charakteristiky polohy.
Definice
Medián je hodnota prostřední jednotky uspořádaného souboru hodnot podle velikosti nebo aritmetický průměr dvou prostředních jednotek v případě, je-li rozsah souboru sudé číslo.
Medián řadíme mezi střední hodnoty a je důležitý hlavně u statistických souborů, které obsahují extrémní hodnoty (extrémně nízké nebo vysoké). Výhodou mediánu je to, že není citlivý na odlehlá pozorování, protože není funkcí všech hodnot souboru.
Poznámka
„Při lichém rozsahu souboru je medián jednoduše vždy hodnota konkrétní prostřední statistické jednotky souboru… Při sudém rozsahu souboru však medián leží mezi dvěma prostředními statistickými jednotkami, proto z těchto dvou jednotek stanovíme průměr (střed) a ten bude označen jako medián.“ [1]
+
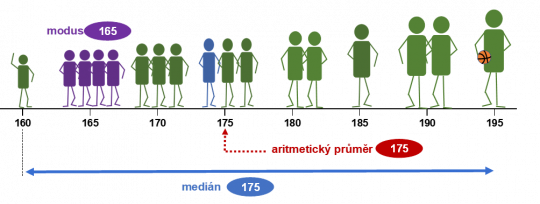
Obr. 6. Ilustrace vztahu modus, medián, aritmetický průměr
Další speciální kategorií kvantilů jsou decily, které dělí soubor na 10 přibližně stejně velkých částí (10% kvantil, 20% kvantil, …, 90% kvantil) a percentily, které rozdělují soubor na 100 přibližně stejně velkých částí (1% kvantil, 2% kvantil, …, 99% kvantil). Příkladem praktického využití percentilů jsou tzv. růstové grafy, dostupné např. zde: http://www.szu.cz/publikace/data/seznam-rustovych-grafu-ke-stazeni.
Velmi pěkně a srozumitelně je problematika kvantilů popsána v publikaci O složitém jednoduše [2], která je dostupná i online.
Příklad
Příklad – medián
Na úřadu práce fiktivního města mají skupinu devíti dobrovolníků. Zde jsou uvedeny počty hodin, které každý z nich odpracoval pro město za poslední měsíc: 0, 12, 18, 24, 29, 37, 48, 55, 90.
Na základě těchto hodnot vypočítejte medián odpracovaných hodin.
Zobrazit řešení
Skrýt řešení
Řešení
Pro ulehčení jsou data již v zadání seřazena od nejnižší hodnoty po nejvyšší.
Můžeme použít vzorec, který nám určí, na jaké pozici, v jakém pořadí se skrývá medián:
.
Protože se jedná o medián (50% kvantil) tak za p dosazujeme 50. Za n dosadíme rozsah našeho souboru 9:
,
.
Z tohoto zápisu vyplývá, že medián se nachází mezi 4,5. až 5,5. pozicí neboli medián najdeme na pátém místě v řadě uspořádaných hodnot. Tento výpočet není pro určení mediánu nezbytně nutný. Stačí si jednoduše říci, kde se nachází polovina z devíti hodnot.
Je ovšem vhodné zkontrolovat počet hodnot v souboru. Pokud se jedná o lichý počet, medián vyjde na konkrétní pozici a číslo. Pokud zkoumaný soubor obsahuje sudý počet hodnot, vyjde medián mezi dvě hodnoty a ty je nutné zprůměrovat.
V našem případě se jednalo o lichý počet hodnot, takže na páté pozici uspořádaného souboru se nachází hodnota 29, medián pro toto zadání je tedy
.
Jak již bylo zmíněno, medián není ovlivněn extrémy (na rozdíl od aritmetického průměru).
Souhrn
Charakteristiky polohy nebo také míry úrovně popisují statistický soubor z hlediska úrovně (velikosti) proměnných. Tyto charakteristiky se dělí na střední hodnoty a kvantily. Mezi charakteristiky středních hodnot řadíme např. aritmetický průměr, harmonický průměr, geometrický průměr či modus. Kvantily se mohou členit na percentily, decily či kvartily. Nejznámějším kvantilem je 50% kvantil neboli medián.
Poznámka
MS EXCEL
Pro výpočet charakteristik polohy můžeme využít jednotlivé statistické funkce anebo „Analýzu dat“. Před prvním spuštěním Analýzy dat je nutné ji nainstalovat: Soubor → Možnosti → Doplňky → Spravovat: Doplňky Excelu → Přejít → zaškrtnout „Analytické nástroje“ a potvrdit. Po instalaci se položka Analýza dat již vždy zobrazuje na kartě Data. Klikneme zde na „Analýza dat“, vybereme možnost „Popisná statistika“ a potvrdíme. Pak je zapotřebí označit oblast vstupních dat, případně upravit další položky z nabídky, zaškrtnout „Celkový přehled“ a potvrdit. Excel vypočítá na zadaných hodnotách většinu základních charakteristik spojených s popisnou statistikou.
Druhá možnost výpočtu se nabízí pomocí statistických funkcí. Před název funkce vždy napíšeme „=“, pak bez mezer následuje název funkce a závorky, do kterých se umístí jednotlivé parametry.
Výpočet, který chceme provést | Funkce v MS Excel |
Rozsah souboru | POČET |
Součet hodnot | SUMA |
Aritmetický průměr | PRŮMĚR |
Harmonický průměr | HARMEAN |
Geometrický průměr | GEOMEAN |
Modus | MODE nebo MODE.SNGL |
Medián | MEDIAN |
Kvantil | PERCENTIL nebo PERCENTIL.INC |
Tyto funkce je možné použít pouze na data zadaná v prostém tvaru. „Pokud bychom chtěli vypočítat charakteristiky váženým způsobem, museli bychom postupně ručním způsobem vkládat jednotlivé části výpočtu daného vzorce.“ [3]
4.2.2
Charakteristiky variability
Charakteristiky variability nebo také měnlivosti jsou ve statistice velice důležité. Můžeme se totiž setkat s tím, že se rozdělené četnosti budou shodovat v charakteristikách polohy, ale lišit ve své variabilitě. Tuto situaci si ukážeme na následujícím obrázku 7.
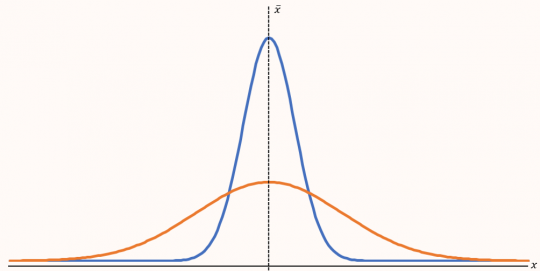
Obr. 7. Rozdělení četností odlišných ve variabilitě
Poznámka
„Měření variability má význam při posuzování vypovídací schopnosti aritmetického průměru. Obecně je možné říci, že vypovídací schopnost aritmetického průměru je tím vyšší, čím je variabilita sledovaného znaku menší.“ [1]
K popisu variability používáme dvě skupiny charakteristik, míry absolutní variability a míry relativní variability. Míry absolutní variability popisují měnlivost statistického souboru ve stejných měrných jednotkách, v jakých je zaznamenána statistická proměnná. Využíváme je např. pro porovnání variability dvou a více souborů z pohledu jedné statistické proměnné (např. variabilita velikosti obuvi u mužů a žen). Mezi míry absolutní variability můžeme zařadit mj. tyto charakteristiky: variační rozpětí, rozptyl, směrodatnou odchylku, kvartilovou odchylku a decilovou odchylku. Všechny tyto charakteristiky vycházejí ve stejných měrných jednotkách jako vstupní hodnoty – až na rozptyl. Ten vychází ve druhé mocnině měrných jednotek sledované proměnné.
Pomocí bezrozměrného čísla vyjadřují variabilitu míry relativní variability. Jedná se většinou o poměr charakteristiky absolutní variability a aritmetického průměru či mediánu. Po vynásobení stem je tedy můžeme interpretovat jako variabilitu v procentech. V tomto textu si ukážeme nejznámější a také nejvíce používanou charakteristiku relativní variability, a to je variační koeficient.
Poznámka
„V literatuře se uvádí, že se [míry relativní variability] používají pro porovnání variability dvou souborů v různých měrných jednotkách, ale vzhledem k tomu, že není stanovena horní hranice, je toto porovnání problematické. Měly by být používány pro porovnání dvou souborů se stejnou úrovní sledované proměnné.“ [3]
VARIAČNÍ ROZPĚTÍ
Definice
Variační rozpětí je rozdíl mezi maximální a minimální hodnotou sledované proměnné.
Variační rozpětí budeme značit velkým písmenem R a vypočítáme ho pomocí následujícího vzorce:
,
kde xmax označuje maximální, nejvyšší hodnotu souboru a xmin naopak nejnižší.
Mezi výhody tohoto ukazatele patří bezesporu jednoduchý výpočet. Nevýhodou je závislost na minimální a maximální hodnotě neboli závislost na extrémech. „Krajní hodnoty řady pozorování, na nichž je variační rozpětí založeno, mohou ovšem být nahodilé. …Výskyt jediné extrémní hodnoty znaku potom vyvolává značnou velikost variačního rozpětí.“ [1] Další nevýhodou je také to, že nepopisuje měnlivost hodnot uvnitř souboru.
ROZPTYL
Definice
Rozptyl je aritmetický průměr čtverců odchylek jednotlivých hodnot proměnné od jejich aritmetického průměru.
Rozptyl je jednou z nejčastěji používaných charakteristik variability. Rozptyl je závislý na proměnlivosti všech hodnot zkoumaného statistického souboru a měří variabilitu okolo aritmetického průměru. Rozptyl budeme značit
. Stejně jako v případě charakteristik polohy i zde, pokud nemáme vstupní hodnoty uspořádány do tabulky četností, používáme pro výpočet rozptylu prostý tvar vzorce.
Rozptyl v prostém tvaru je možné vypočítat podle následujícího vzorce:
,
kde x1, x2, …, xn jsou zjištěné neuspořádané hodnoty o celkovém počtu n a
je aritmetickým průměrem těchto hodnot.
Nebo můžeme použít tzv. výpočtový tvar:
.
Ať už zvolíme pro výpočet rozptylu v prostém tvaru jakýkoli z těchto dvou vzorců, pokud je budeme aplikovat na stejné vstupní hodnoty, výsledek musí být shodný.
Pokud zjištěné hodnoty zkoumaného statistického souboru uspořádáme do tabulky četností, používáme pro výpočet rozptylu jeho vážený tvar.
Rozptyl ve váženém tvaru můžeme zapsat následujícím způsobem:
.
Četnosti, které zde značíme n1, n2, …, nk, představují váhu jednotlivých obměn proměnné x1, x2, …, xk.
I zde je možné výpočet provést pomocí vzorce ve výpočtovém tvaru:
.
Ovšem četnosti, které zde zastupují váhu jednotlivých obměn zkoumané statistické proměnné, mohou být také zapsány v relativním vyjádření a také ve výpočtovém tvaru:
,
.
Video 3. Výpočet váženého rozptylu
Další příklady k procvičení najdete v kapitole Kontrolní otázky a příklady.
Stejně tak, jako má aritmetický průměr zajímavé a užitečné vlastnosti, najdeme je i u rozptylu.
Vlastnosti rozptylu
- Rozptyl konstanty je roven nule: .
- Přičteme-li k jednotlivým hodnotám proměnné nenulovou konstantu k, rozptyl se nezmění: .
- Násobíme-li jednotlivé hodnoty proměnné nenulovou konstantou k, rozptyl je násoben čtvercem této konstanty: .
- Rozptyl součtu nebo rozdílu hodnot dvou proměnných, kde , je roven součtu rozptylů obou proměnných zvětšenému nebo zmenšenému o dvojnásobek tzv. kovariance, tj. .
- Je-li statistický soubor rozdělen do m dílčích podsouborů, v nichž známe jednotlivé dílčí rozptyly , dílčí průměry a počty pozorování n1, n2, …, nm, resp. p1, p2, …, pm, pak rozptyl celého souboru je dán součtem rozptylu dílčích (skupinových) průměrů a průměru z dílčích (skupinových) rozptylů, kde vahami jsou četnosti podsouborů: , resp. .
Poznámka
„Vztah o dílčích rozptylech tedy umožňuje výpočet celkového rozptylu i bez znalosti původních hodnot znaku. Tento rozklad dále umožňuje také hodnotit, jak dalece je celkový rozptyl ovlivněn variabilitou uvnitř skupin a jak dalece variabilitou mezi skupinami.“ [1]
Video 4. Vlastnosti aritmetického průměru a rozptylu
SMĚRODATNÁ ODCHYLKA
Definice
Směrodatná odchylka je druhá odmocnina z rozptylu.
Budeme ji značit sx a vypočítáme ji podle tohoto vzorce:
.
Příklad
Příklad – vlastnosti rozptylu / směrodatné odchylky 1
Na tomto příkladu si procvičíme vlastnosti rozptylu, resp. směrodatné odchylky.
Hodnota rozptylu kapesného u dětí se rovná hodnotě 900.
Vaším úkolem je vypočítat, jak se změní směrodatná odchylka kapesného dětí, jestliže:
- každé dítě dostane přidáno 50 Kč,
- každé dítě dostane dvojnásobek kapesného,
- každé dítě dostane přidáno 10 % ze stávajícího kapesného.
Zobrazit řešení
Skrýt řešení
Řešení
- každé dítě dostane přidáno 50 Kč
Tato úprava se týká druhé vlastnosti rozptylu, která hovoří o přičítání nenulové konstanty
.
Nová hodnota rozptylu, a tím pádem ani směrodatné odchylky se nezmění, neboť přičítání konstanty ke všem původním hodnotám nemá vliv na rozptyl ani směrodatnou odchylku.
My chceme znát hodnotu směrodatné odchylky:
.
Původní hodnota rozptylu byla 900, odmocněním získáme směrodatnou odchylku, která se rovná 30. Na aritmetický průměr působí přičtení konstanty tak, že dojde k jeho posunu o velikost konstanty. Pro rozptyl to znamená, že se sice všechny hodnoty posunuly o konstantu, ale neposunuly se od sebe navzájem, jejich vzdálenost mezi sebou se nemění.
- každé dítě dostane dvojnásobek kapesného
Tato úprava se týká třetí vlastnosti rozptylu, která hovoří o násobení nenulovou konstantou
.
Musíme tedy vzít původní hodnotu rozptylu kapesného, vynásobit ho 4× a získáme hodnotu nového rozptylu.
V našem příkladu se ale ptáme na směrodatnou odchylku:
.
Nová hodnota směrodatné odchylky kapesného je rovna 60.
- každé dítě dostane přidáno 10 % ze stávajícího kapesného
Tato úprava se týká také třetí vlastnosti rozptylu, která hovoří o násobení nenulovou konstantou.
Vezmeme původní hodnotu rozptylu kapesného, vynásobíme ji číslem 1,1 (nárůst na 110 % původní hodnoty) a získáme hodnotu nového rozptylu.
Výpočet pro směrodatnou odchylku vypadá následovně:
.
Nová hodnota směrodatné odchylky kapesného je rovna 33.
KVARTILOVÁ ODCHYLKA
Definice
Kvartilová odchylka je aritmetický průměr kladných odchylek sousedních kvartilů.
Kvartilovou odchylku můžeme zapsat v tomto tvaru:
.
Rozdíl, který je uvedený v čitateli zlomku, nazýváme kvartilové rozpětí. Nevýhodou kvartilové odchylky je to, že nepopisuje měnlivost všech hodnot zkoumané proměnné.
Příklad
Příklad – kvartilová odchylka
Z dat Českého statistického úřadu vyplývá, že v roce 2017 dolní kvartil mezd v České republice činil 19 674,- Kč, zatímco horní kvartil dosahoval hodnoty 35 550,- Kč.
Vypočítejte kvartilovou odchylku mezd.
Zobrazit řešení
Skrýt řešení
Řešení
Vzdálenost od dolního k hornímu kvartilu nás informuje o tom, v jakých mezích se pohybuje prostředních 50 % mezd v České republice v roce 2017, tj.
.
Samotnou kvartilovou odchylku vypočítáme jednoduše
Kvartilová odchylka mezd činila v roce 2017 v České republice 7 938,- Kč.
DECILOVÁ ODCHYLKA
Definice
Decilová odchylka je aritmetický průměr kladných odchylek sousedních decilů.
Decilovou odchylku můžeme zapsat v tomto tvaru
.
Ani decilová odchylka nedokáže zachytit měnlivost všech hodnot zkoumané proměnné. Její výhodou však je robustnost vůči extrémním hodnotám. Není ovlivněna odlehlými hodnotami.
Poznámka
„Obecnou nevýhodou kvantilových měr variability je to, že nezachycují variabilitu všech hodnot znaku a vzhledem k jejich konstrukci je nelze hlouběji analyzovat a rozkládat. S ohledem na tyto skutečnosti a na vlastnosti, které zařazují rozptyl a směrodatnou odchylku do širších souvislostí s ostatními charakteristikami jednorozměrných i vícerozměrných souborů, lze považovat rozptyl a směrodatnou odchylku za nejdůležitější charakteristiky variability.“ [1]
VARIAČNÍ KOEFICIENT
Definice
Variační koeficient je podíl směrodatné odchylky a aritmetického průměru sledované proměnné.
Variační koeficient patří mezi nejznámější a také nejčastěji používané míry relativní variability. Jak již bylo řečeno dříve, míry relativní variability vyjadřují měnlivost pomocí bezrozměrného čísla.
Variační koeficient tedy vypočítáme pomocí následujícího vzorce:
.
Po vynásobení stem udává variabilitu v procentech.
Poznámka
„Možnost interpretovat variační koeficient v procentech dost často uživatele svádí k chápání jeho definičního oboru od 0 % do 100 %, resp. tedy od 0 do 1. Je to zásadní omyl. Vzhledem k tomu, že nelze najít žádné omezení na číselné ose a zprava pro velikost směrodatné odchylky, může obecně být směrodatná odchylka i větší než aritmetický průměr stejných hodnot, a pak tedy variační koeficient je větší než 1 (resp. větší než 100 %). A protože průměr může být obecně i číslo záporné (např. průměrná venkovní středoevropská teplota v lednu či záporný zisk v souboru podniků), nelze vyloučit že, variační koeficient tím pádem… je číslo záporné.“ [1]
Souhrn
Míry absolutní variability popisují měnlivost statistického souboru ve stejných měrných jednotkách, v jakých je zaznamenána statistická proměnná. Mezi míry absolutní variability můžeme zařadit mj. tyto charakteristiky: variační rozpětí, rozptyl, směrodatnou odchylku, kvartilovou odchylku a decilovou odchylku. Pomocí bezrozměrného čísla vyjadřují variabilitu míry relativní variability. Nejvíce používanou charakteristiku relativní variability je variační koeficient.
Poznámka
MS EXCEL
Pro výpočet charakteristik polohy můžeme využít jednotlivé statistické funkce anebo „Analýzu dat“. Klikneme zde na „Analýza dat“ a vybereme možnost „Popisná statistika“ a potvrdíme. Pak je zapotřebí označit oblast vstupních dat, případně upravit další položky z nabídky, zaškrtnout „Celkový přehled“ a potvrdit. Excel vypočítá na zadaných hodnotách většinu základních charakteristik spojených s popisnou statistikou.
Druhá možnost výpočtu se nabízí pomocí statistických funkcí. Před název funkce vždy napíšeme „=“, pak bez mezer následuje název funkce a závorky, do kterých se umístí jednotlivé parametry.
Výpočet, který chceme provést | Funkce v MS Excel |
Minimum | MIN |
Maximum | MAX |
Rozptyl | VAR nebo VAR.P |
Směrodatná odchylka | SMODCH nebo SMODCH.P |
Opět tyto funkce je možné použít pouze na data zadaná v prostém tvaru.
4.2.3
Charakteristiky šikmosti a špičatosti
KOEFICIENT ŠIKMOSTI
Definice
Koeficient šikmosti popisuje soubor hodnot sledované proměnné z hlediska koncentrace nízkých a vysokých hodnot sledované proměnné v porovnání se symetrickým rozdělením četností.
Koeficient šikmosti (asymetrie), který budeme značit αx, můžeme počítat pomocí tohoto vzorce:
,
kde x1, x2, …, xk představují jednotlivé obměny zkoumané proměnné,
je aritmetický průměr z těchto hodnot a
je směrodatná odchylka, která je zde umocněna na třetí.
Pokud nám vyjde hodnota koeficientu šikmosti nulová, znamená to, že hodnoty zkoumané proměnné jsou rovnoměrně rozděleny vlevo a vpravo od středu. Takovéto rozdělení je symetrické kolem střední hodnoty. Typickým příkladem takového rozdělení je tzv. normální rozdělení, Gaussova křivka. Jestliže nám koeficient šikmosti vychází kladný, pak jsou v souboru více koncentrovány (nahuštěny) nižší hodnoty ve srovnání s vyššími. Tomuto typu rozdělení se také říká kladně sešikmené. Pro kladně sešikmené rozdělení zpravidla platí, že modus je menší než medián a ten je menší než střední hodnota. Pokud nám koeficient šikmosti vychází záporný, pak jsou v souboru více koncentrovány vyšší hodnoty ve srovnání s nižšími. Tomuto typu rozdělení se tedy říká záporně sešikmené. A zpravidla pro něj platí, že střední hodnota je menší než medián a ten je menší než modus.
+
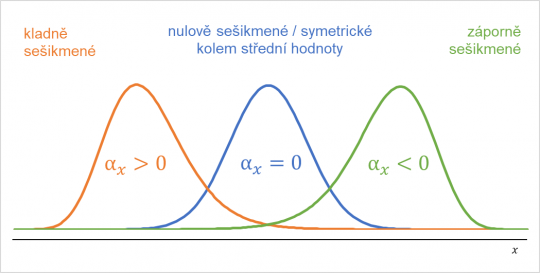
Obr. 8. Kladně, nulově a záporně sešikmené rozdělení četností
KOEFICIENT ŠPIČATOSTI
Definice
Koeficient špičatosti popisuje soubor hodnot sledované proměnné z hlediska koncentrace hodnot v souboru kolem střední hodnoty.
Koeficient špičatosti značíme βx a spočítáme ho pomocí následujícího vzorce:
,
kde x1, x2, …, xk představují jednotlivé obměny zkoumané proměnné,
je aritmetický průměr z těchto hodnot a
je směrodatná odchylka, která je zde umocněna čtvrtou mocninou.
Čím vyšší nám vyjde hodnota koeficientu špičatosti, tím je rozdělení četností špičatější, strmější. Jestliže hodnota koeficientu špičatosti vyjde nulová, znamená to, že rozdělení má tvar Gaussovy křivky. Jestliže nám koeficient špičatosti vychází kladný, pak jsou v souboru více koncentrovány, nahuštěny kolem středu. Pokud nám koeficient špičatosti vychází záporný, pak jsou hodnoty více rozptýlené, vzdálené od středu.
+
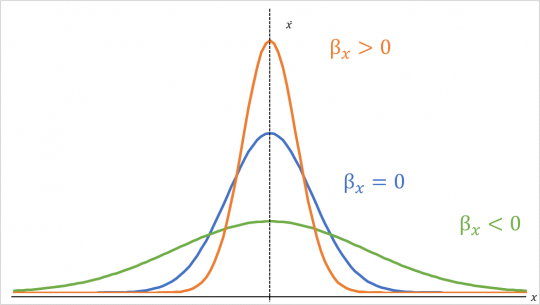
Obr. 9. Špičatost rozdělení četností
Souhrn
Koeficient šikmosti popisuje soubor hodnot sledované proměnné z hlediska koncentrace nízkých a vysokých hodnot sledované proměnné v porovnání se symetrickým rozdělením četností. Koeficient špičatosti popisuje soubor hodnot sledované proměnné z hlediska koncentrace hodnot v souboru kolem střední hodnoty.
Poznámka
MS EXCEL
Pro výpočet charakteristik polohy můžeme využít jednotlivé statistické funkce anebo „Analýzu dat“.
Chceme-li provádět výpočty pomocí statistických funkcí, před název funkce vždy napíšeme „=“, pak bez mezer následuje název funkce a závorky, do kterých se umístí jednotlivé parametry.
Výpočet, který chceme provést | Funkce v MS Excel |
Šikmost | SKEW nebo SKEW.P |
Špičatost | KURT |
Opět tyto funkce je možné použít pouze na data zadaná v prostém tvaru.