3.4
Vybraná rozdělení spojité náhodné veličiny
V této části se budeme věnovat některým pravděpodobnostním rozdělením spojité náhodné veličiny. K popisu těchto rozdělení budeme využívat hustotu pravděpodobnosti a distribuční funkci. Jednotlivá rozdělení zde budou popsána, budou uvedeny příklady jejich použití a také charakteristiky (střední hodnota a rozptyl) náhodné veličiny.
Jak už bylo napsáno dříve, v současné době se téměř veškeré statistické výpočty provádí za pomocí výpočetní techniky. V případě spojitých pravděpodobnostních rozdělení to platí dvojnásob, neboť se zde pracuje s integrály a derivacemi funkcí. V tomto výukovém materiálu bude pozornost věnována hlavně ukázce principu výpočtu a vše bude demonstrováno na zjednodušených příkladech, které je možné řešit pouze za pomoci kalkulačky. V závěru této části je opět uveden stručný návod, kde je popsána možnost využití MS Excelu pro řešení této problematiky.
ROVNOMĚRNÉ ROZDĚLENÍ
Rovnoměrné rozdělení řadíme mezi nejjednodušší pravděpodobnostní rozdělení spojité náhodné veličiny. Toto pravděpodobnostní rozdělení využijeme tam, kde má náhodná veličina X konstantní hustotu pravděpodobnosti na celém definičním oboru. Jinak řečeno, má stejnou možnost výskytu v celém intervalu
. Příkladem využití tohoto rozdělení v praxi může být čekání na odjezd dopravního prostředku (v pravidelném časovém intervalu) nebo chyby při zaokrouhlování.
Definice
Náhodná veličina X se přibližně řídí rovnoměrným rozdělením s parametry a a b:
.
Hustotu pravděpodobnosti náhodné veličiny s rovnoměrným rozdělením je možné vyjádřit jako:
.
Distribuční funkci je možné zapsat takto:
.
Poznámka
Nenechte se zmást zvláštním způsobem zápisu hustoty pravděpodobnosti a distribuční funkce, kde se vyskytuje veliká složená závorka (pouze její levá část). Jedná se o zápis, který zachycuje všechny části těchto funkcí. Např. u distribuční funkce rovnoměrného rozdělení první řádek říká, že pokud je x menší než dolní hranice a, pak je distribuční funkce nulová. Druhý řádek znamená, že pokud se x pohybuje mezi a a b, pak je možné distribuční funkci vypočítat podle tohoto výrazu
. Ve třetím řádku je řečeno, že pokud x nabude hodnoty stejné nebo větší než horní hranice b, pak se bude distribuční funkce rovnat jedné. Doporučuji podívat se na obr. 20, zde je vše názorně ukázáno.
Definice
Střední hodnota rovnoměrného rozdělení se vypočítá takto:
.
Rozptyl rozdělení zapíšeme tímto způsobem:
.

Obr. 19. Hustota pravděpodobnosti rovnoměrného rozdělení

Obr. 20. Distribuční funkce rovnoměrného rozdělení
Příklad
Pražské metro na trase C jezdí v době dopravní špičky v pravidelných tříminutových intervalech.
Jaká je pravděpodobnost, že pokud právě přijdeme v náhodně vybraný okamžik na stanici metra, přijede souprava do minuty?
Jaká je střední hodnota a rozptyl pro toto rozdělení?
Zobrazit řešení
Řešení
Dosadíme do vzorce pro výpočet distribuční funkce rovnoměrného rozdělení
.
Ze zadání je jasné, že:
,
.
Náhodná veličina X se řídí rovnoměrným rozdělením v následujícím tvaru:
,
,
.
Střední hodnota rovnoměrného rozdělení se vypočítá jako:
.
Průměrná doba do příjezdu soupravy pražského metra na trase C v době dopravní špičky je 1,5 minuty.
Rozptyl rozdělení zapíšeme tímto způsobem:
.
EXPONENCIÁLNÍ ROZDĚLENÍ
Exponenciální rozdělení se používá nejčastěji při výpočtu pravděpodobnosti doby životnosti výrobku, modelování času radioaktivního rozpadu a v systémech hromadné obsluhy. Náhodná veličina X označuje dobu, během které nastane sledovaný jev. Exponenciální rozdělení má dva parametry A a δ. „Parametr A představuje počáteční dobu, během které sledovaný jev nastat nemůže. Může to být například doba, během které trvá ověření platební karty při době obsluhy. Většinou však tato doba bývá nulová a hovoříme pak o jednoparametrickém exponenciálním rozdělení.“ [1]
Definice
Náhodná veličina X se přibližně řídí exponenciálním rozdělením s parametry A a δ:
.
Hustotu pravděpodobnosti náhodné veličiny s exponenciálním rozdělením je možné vyjádřit jako:
.
Distribuční funkci můžeme zapsat takto:
.
Definice
Střední hodnota exponenciálního rozdělení se vypočítá takto:
.
Rozptyl exponenciálního rozdělení zapíšeme následovně:
.
+
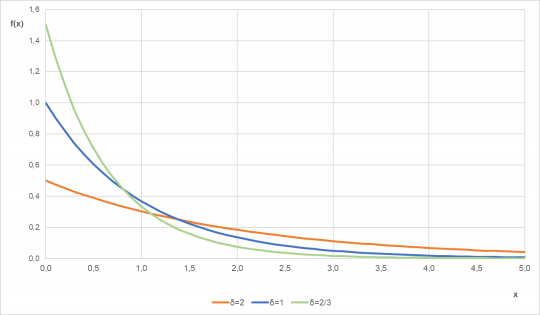
Obr. 21. Hustota pravděpodobnosti exponenciálního rozdělení pro různé parametry
+
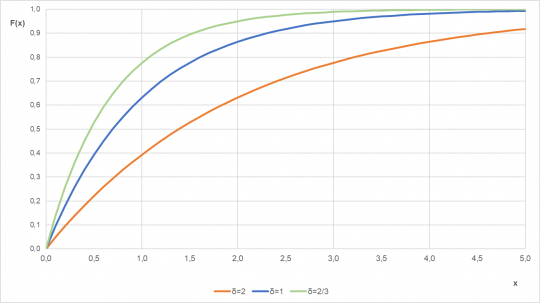
Obr. 22. Distribuční funkce exponenciálního rozdělení pro různé parametry
Příklad
Doba životnosti mikrovlnné trouby se řídí exponenciálním rozdělením se střední hodnotou 5 000 hodin.
Jaká je pravděpodobnost, že se mikrovlnná trouba porouchá během prvních 1 000 hodin?
Jaká je střední hodnota a rozptyl pro toto rozdělení?
Zobrazit řešení
Řešení
Dosadíme do vzorce pro výpočet distribuční funkce exponenciálního rozdělení
.
Ze zadání je jasné, že:
.
Parametr A je roven nule, protože mikrovlnná trouba se může porouchat okamžitě po prvním spuštění.
Náhodná veličina X se řídí exponenciálním rozdělením v následujícím tvaru:
,
,
.
Pravděpodobnost, že se mikrovlnná trouba porouchá během prvních 1 000 hodin provozu, se rovná 0,181.
Střední hodnota exponenciálního rozdělení se vypočítá jako:
.
Průměrná doba do poruchy mikrovlnné trouby je 5 000 hodin.
Rozptyl exponenciálního rozdělení vypočítáme jako druhou mocninu δ
.
NORMÁLNÍ ROZDĚLENÍ
Normální rozdělení je nejdůležitějším pravděpodobnostním rozdělením. Využíváme ho jako pravděpodobnostní model pro chování mnoha náhodných jevů z oblasti přírodních věd, techniky i ekonomie. „Klasickým příkladem tohoto rozdělení je rozdělení náhodných chyb vzniklých při měření nějaké veličiny. Při opakovaném měření téže veličiny za stejných podmínek způsobují náhodné (nekontrolovatelné) vlivy odchylky od skutečné hodnoty měřené veličiny.“ [1]Řídí se jím náhodná veličina, jejíž kolísání je způsobeno součtem drobných, vzájemně nezávislých vlivů. Normální rozdělení má dva parametry μ a
, které jsou zároveň střední hodnotou a rozptylem náhodné veličiny. Pomocí normálního rozdělení můžeme aproximovat (upravit) řadu jiných rozdělení, spojitých i nespojitých. „Předpoklad normality rozdělení je požadavek mnoha statistických metod a jeho porušení má více či méně negativní důsledky na výsledky a možnost aplikace jednotlivých metod.“ [1]
Definice
Náhodná veličina X se přibližně řídí normálním rozdělením s parametry μ a
:
.
Hustotu pravděpodobnosti náhodné veličiny s normálním rozdělením (tzv. Gaussovu křivku) můžeme zapsat jako:
,
kde
,
.
Distribuční funkce má tento tvar:
.
Poznámka
Abychom nemuseli počítat integrály a derivace funkcí, využijeme transformace náhodné veličiny X na normovanou náhodnou veličinu U, která je tabelována. Postup jejího výpočtu je uveden dále.
Definice
Střední hodnota normálního rozdělení se vypočítá takto:
.
Rozptyl normálního rozdělení zapíšeme jako:
.

Obr. 23. Hustota pravděpodobnosti normálního rozdělení pro různé parametry
Z obrázku 23 je jasně zřetelné, proč se o normálním rozdělení říká, že je symetrické kolem střední hodnoty. U normálního rozdělení vždy platí, že střední hodnota se rovná také modu (nejčastěji zastoupené hodnotě v souboru) a mediánu (polovina uspořádaného souboru).
+
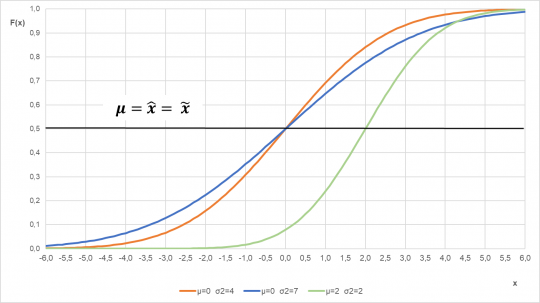
Obr. 24. Distribuční funkce normálního rozdělení pro různé parametry
Pro zjednodušení se většinou používá normované normální rozdělení, které je speciálním případem normálního rozdělení. Hodnoty tohoto rozdělení jsou tabelovány (zapsány v tabulkách), což značně usnadňuje výpočty.
Definice
Náhodná veličina U se řídí normovaným normálním rozdělením s parametry
a
, tzn. normálním rozdělením se střední hodnotou 0 a rozptylem 1:
.
Transformaci náhodné veličiny X na normovanou normální veličinu U provádíme pomocí tohoto výrazu:
.
Hustotu pravděpodobnosti náhodné veličiny s normovaným normálním rozdělením zapíšeme jako:
,
kde
Distribuční funkce má tento tvar:
.
Poznámka
Ve chvíli, kdy zapisujeme distribuční funkci normované normální veličiny U, změníme i označení samotné distribuční funkce na
. Pokud tedy hovoříme o distribuční funkci normální veličiny, píšeme F(x), když o distribuční funkci normované normální veličiny, pak
.
Definice
Střední hodnota normovaného normálního rozdělení se vypočítá takto:
.
Rozptyl normovaného normálního rozdělení zapíšeme jako:
.
Kvantil normovaného normálního rozdělení vypočítáme pomocí následujícího výrazu:
.
Definice
Distribuční funkce normované normální veličiny je symetrická kolem nuly a platí pro ni:
.
Pro kvantily normovaného normálního rozdělení platí tento vztah:
.
Jestliže potřebujeme nalézt pravděpodobnost, že náhodná veličina X nabývá hodnoty z intervalu
, poslouží nám tento zápis:
.
Díky vlastnostem distribuční funkce můžeme tento zápis ještě upravit do následujícího tvaru:
.
Video 4. Příklad na normované normální rozdělení
Příklad
Automat plní moukou balíky o váze 5 kg. Náhodná veličina X představuje odchylku v gramech (chybu plnění) od požadované hodnoty 5 kg. Tato chyba má normální rozdělení s parametry μ = 0 a σ2 = 64.
Určete:
- pravděpodobnost, že váha balíku bude větší než 5 016 g,
- pravděpodobnost, že se váha balíku bude pohybovat v intervalu ,
- takovou hodnotu x, kterou odchylka od průměrné váhy balíku nepřekročí s pravděpodobností 0,99.
- takovou hodnotu x, pro kterou se odchylka od průměrné váhy balíku s pravděpodobností 0,9 bude pohybovat v intervalu .
- Jaká je střední hodnota a rozptyl pro toto rozdělení?
Zobrazit řešení
Řešení
Ve všech případech budeme dosazovat do vzorců pro normovanou normální veličinu.
Ze zadání je jasné, že
,
.
Náhodná veličina X se řídí normálním rozdělením v následujícím tvaru:
.
- pravděpodobnost, že váha balíku bude větší než 5 016 g
Zde je nutné řešit vše přes doplňkový jev. To, že váha balíku bude větší minimálně o 16 gramů neumíme matematicky vyřešit jinak než jako „1 - distribuční funkce v hodnotě 16“.
+
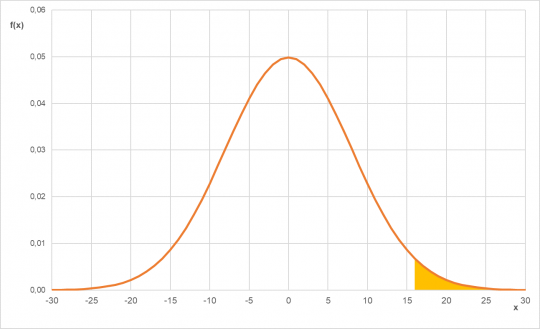
Obr. 25. Pravděpodobnost P(X > 16) pro normální rozdělení N(0;64)
Pravděpodobnost, že automat balík mouky přesype o více než 16 gramů, se rovná přibližně 0,023.
- pravděpodobnost, že se váha balíku bude pohybovat v intervalu
U tohoto zadání se nenechte zmást tím, že je uvedena váha balíku. Nás zajímá jen odchylka od střední hodnoty 5 000 gramů, což je
gramů.
+
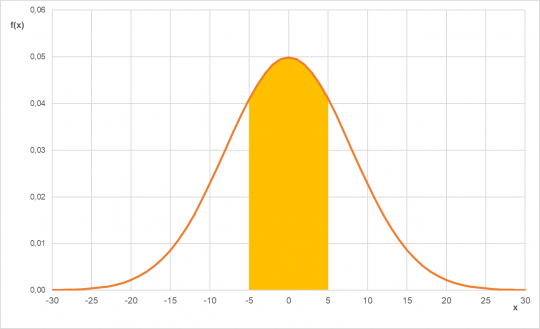
Obr. 26. Pravděpodobnost
pro normální rozdělení N(0;64)
Pravděpodobnost, že se balík mouky bude odchylovat od průměru o
gramů, je rovna 0,468.
- takovou hodnotu x, kterou odchylka od průměrné váhy balíku nepřekročí s pravděpodobností 0,99
V tomto zadání se již neptáme na to, s jakou pravděpodobností něco (ne)nastane. Pravděpodobnost je dána a nás zajímá, pro jaké x toto platí. Tento typ úloh se řeší pomocí kvantilů.
+
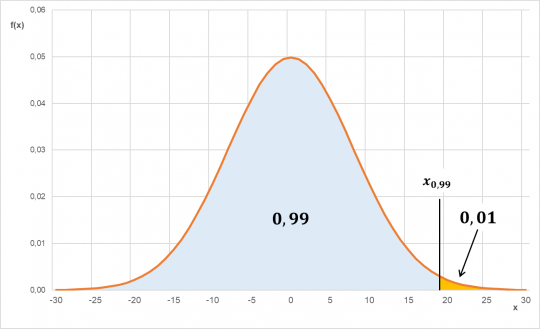
Obr. 27. Kvantil x0,99 pro normální rozdělení N(0;64)
Budeme hledat 99% kvantil.
S pravděpodobností 0,99 odchylka od průměrné váhy balíku nepřekročí 18,61 gramů.
- takovou hodnotu x, pro kterou se odchylka od průměrné váhy balíku s pravděpodobností 0,9 bude pohybovat v intervalu
Toto zadání budeme také řešit pomocí kvantilů, ale pozor, nehledáme jedno x, ale dvě, tudíž kvantily budou také dva.
+
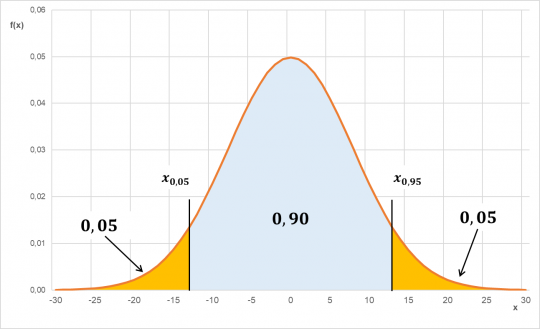
Obr. 28. Kvantil x0,05 a x0,95 pro normální rozdělení N(0;64)
Budeme hledat 5% a 95% kvantil.
S pravděpodobností 0,9 se odchylka od průměrné váhy balíku bude pohybovat v intervalu
gramů.
- Jaká je střední hodnota a rozptyl pro toto rozdělení?
Střední hodnota normálního rozdělení se rovná
.
Průměrná odchylka od balíku vážícího 5 kg je rovna nule.
Rozptyl normálního rozdělení vyjádříme takto
.
LOGARITMICKO-NORMÁLNÍ ROZDĚLENÍ
Definice
Logaritmicko-normální rozdělení, někdy se také můžeme setkat s kratším označením lognormální rozdělení, je rozdělení náhodné veličiny, která má tento tvar:
,
kde
.
Náhodná veličina X se přibližně řídí logaritmicko-normálním rozdělením s parametry μ a
:
.
Hustotu pravděpodobnosti náhodné veličiny s logaritmicko-normálním rozdělením můžeme zapsat jako:
.
Distribuční funkci logaritmicko-normálního rozdělení můžeme určit pomocí distribuční funkce normovaného normálního rozdělení:
.
Tímto rozdělením se řídí např. příjmová rozdělení a je tzv. kladně sešikmené, viz obrázek 29.
Poznámka
Na rozdíl od normálního rozdělení se v případě logaritmicko-normálního parametry
a
nerovnají střední hodnotě a rozptylu pro toto rozdělení.
Definice
Střední hodnota logaritmicko-normálního rozdělení se vypočítá takto:
.
Rozptyl logaritmicko-normálního rozdělení zapíšeme jako:
.
Pro p% kvantily logaritmicko-normálního rozdělení platí:
,
kde
značí p-procentní kvantil normovaného normálního rozdělení.

Obr. 29. Hustota pravděpodobnosti logaritmicko-normálního rozdělení pro různé parametry
+
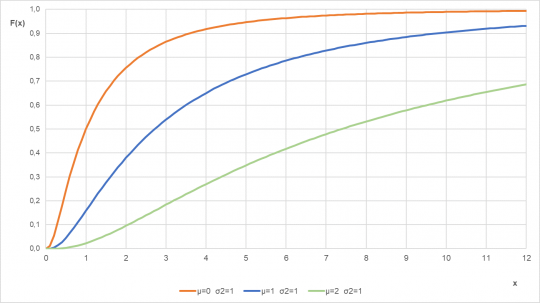
Obr. 30. Distribuční funkce logaritmicko-normálního rozdělení pro různé parametry
Příklad
Vypočítejte hodnotu distribuční funkce logaritmicko-normálního rozdělení
v bodě
a 90% kvantil.
Zobrazit řešení
Řešení
Distribuční funkci logaritmicko-normálního rozdělení určujeme pomocí normované normální veličiny
.
90% kvantil vypočítáme podle tohoto výrazu
,
.
Následující rozdělení budou popsána jen v krátkosti, protože výpočet jejich hustoty pravděpodobnosti i distribuční funkce není jednoduchý. Avšak jedná se o velmi důležitá rozdělení, která jsou hojně využívána v oblasti matematické statistiky (teorie odhadů, testování hypotéz).
CHÍ-KVADRÁT ROZDĚLENÍ
„Chí-kvadrát rozdělení má rozsáhlé použití v teorii odhadu a testování hypotéz, zejména při ověřování předpokladu, zda empirické rozdělení četností má či nemá pravděpodobnostní rozdělení určitého druhu, při ověřování nezávislosti kvalitativních znaků a jinde.“ [1]
Definice
Jsou-li U1, U2, …, Uv nezávislé náhodné veličiny, z nichž každá má normované normální rozdělení N(0;1), pak součet čtverců těchto náhodných veličin je veličinou
:
,
kde
je počet stupňů volnosti, který označuje počet nezávislých sčítanců.
Výpočet hustoty pravděpodobnosti pro chí-kvadrát rozdělení je velmi komplikovaný, takže zde nebude uváděn.
Definice
Střední hodnota chí-kvadrát rozdělení se vypočítá takto:
.
Rozptyl chí-kvadrát rozdělení zapíšeme jako:
.
Pro různé kombinace υ a p jsou hodnoty kvantilů rozdělení
tabelovány. Pro daný počet stupňů volnosti musí být splněn vztah
. S rostoucím počtem stupňů volnosti se chí-kvadrát rozdělení blíží normálnímu rozdělení.
Definice
Pro
je možné kvantily chí-kvadrát rozdělení stanovit pomocí kvantilů normovaného normálního rozdělení:
,
kde
značí p-procentní kvantil normovaného normálního rozdělení.
+

Obr. 31. Hustota pravděpodobnosti chí-kvadrát rozdělení pro různé parametry
+
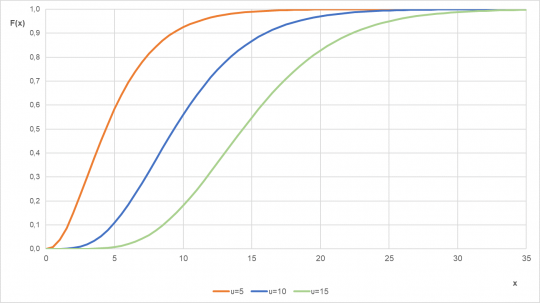
Obr. 32. Distribuční funkce chí-kvadrát rozdělení pro různé parametry
ROZDĚLENÍ T (STUDENTOVO)
Rozdělení t je kombinací nám již známého normovaného normálního rozdělení a chí-kvadrát rozdělení. Za jeho vznikem stojí Angličan William Sealy Gosset (1876–1937), který publikoval pod pseudonymem Student. „[William Sealy Gosset] nebyl povoláním statistikem, jak by se opět dalo očekávat. Byl povoláním chemik a začátkem našeho století pracoval v anglickém pivovaru Guinness. A toto rozdělení nevymyslel proto, že by se nudil, ale proto, že potřeboval vyvozovat na základě velmi malých vzorků použitelné závěry. A k těmto účelům se toto rozdělení používá dodnes.“ [5]Často se s tímto rozdělením můžeme setkat v matematické statistice, konkrétně při odhadech a testování hypotéz. „Užívá se k testování hypotéz o střední hodnotě náhodného výběru, pokud je rozptyl neznámý… Užívá se k testování hypotéz o shodě středních hodnot dvou náhodných výběrů… t rozdělení je vhodným prostředkem pro analýzu výsledků regresní analýzy.“ [5]
Definice
Uvažujme dvě nezávislé náhodné veličiny U(0;1) a
.
Veličina t má Studentovo rozdělení:
,
kde
je počet stupňů volnosti.
Pro
se t rozdělení blíží normovanému normálnímu. V praxi, pokud platí, že
, pak t rozdělení je již považováno za normální.
+

Obr. 33. Hustota pravděpodobnosti t rozdělení pro různé parametry
+

Obr. 34. Distribuční funkce t rozdělení pro různé parametry
Pro různé kombinace υ a p jsou hodnoty kvantilů rozdělení
tabelovány.
ROZDĚLENÍ F (FISHEROVO-SNEDECOROVO)
Rozdělení F je odvozeno od podílu dvou nezávislých náhodných veličin, které se řídí chí-kvadrát rozdělením dělených stupni volnosti. Rozdělení bývá také označováno Fisherovo-Snedecorovo rozdělení, podle Ronalda Fishera (1890–1962) a George W. Snedecora (1881–1974). I toto rozdělení má své uplatnění v oblasti matematické statistiky. „Toto rozdělení má opět široké uplatnění, především při hodnocení výsledků statistických analýz. Používá se především: K testu o shodnosti rozptylů dvou náhodných výběrů. K testům o shodě středních hodnot pro více náhodných výběrů. K testům v regresní analýze.“ [5]
Definice
Uvažujme dvě nezávislé náhodné veličiny
a
.
Náhodná veličina F má Fisherovo-Snedecorovo rozdělení:
,
kde
a
je počet stupňů volnosti.
Toto rozdělení má dva parametry, kterými jsou stupně volnosti
a
.
+
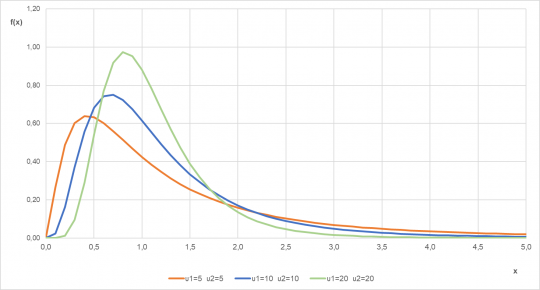
Obr. 35. Hustota pravděpodobnosti F rozdělení pro různé parametry
+
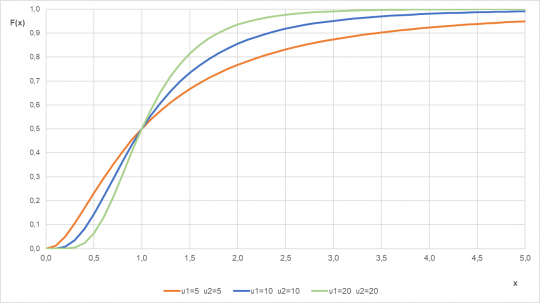
Obr. 36. Distribuční funkce F rozdělení pro různé parametry
Pro různé kombinace
a
jsou hodnoty kvantilů rozdělení
tabelovány.
Souhrn
Rovnoměrné rozdělení řadíme mezi nejjednodušší pravděpodobnostní rozdělení spojité náhodné veličiny. Příkladem využití tohoto rozdělení v praxi může být čekání na odjezd dopravního prostředku (v pravidelném časovém intervalu) nebo chyby při zaokrouhlování. Exponenciální rozdělení se používá nejčastěji při výpočtu pravděpodobnosti doby životnosti výrobku, modelování času radioaktivního rozpadu a v systémech hromadné obsluhy. Náhodná veličina X označuje dobu, během které nastane sledovaný jev. Normální rozdělení je nejdůležitějším pravděpodobnostním rozdělením. Využíváme ho jako pravděpodobnostní model pro chování mnoha náhodných jevů z oblasti přírodních věd, techniky i ekonomie. Příkladem je rozdělení náhodných chyb vzniklých při měření nějaké veličiny. Pomocí normálního rozdělení můžeme aproximovat (upravit) řadu jiných rozdělení, spojitých i nespojitých. Logaritmicko-normální rozdělení je tzv. kladně sešikmené a řídí se jím např. příjmová rozdělení. Chí-kvadrát rozdělení má rozsáhlé použití v teorii odhadu a testování hypotéz, zejména při ověřování předpokladu, zda empirické rozdělení četností má či nemá pravděpodobnostní rozdělení určitého druhu, při ověřování nezávislosti kvalitativních znaků a jinde. T rozdělení je vhodným prostředkem pro analýzu výsledků regresní analýzy. Rozdělení F je odvozeno od podílu dvou nezávislých náhodných veličin, které se řídí chí-kvadrát rozdělením, dělených stupni volnosti a uplatňuje se především při hodnocení výsledků statistických analýz.
Poznámka
MS EXCEL
Pro výpočet pravděpodobnostních rozdělení můžeme využít jednotlivé statistické funkce.
Před název funkce vždy napíšeme „=“, pak následuje název funkce bez mezer a závorky, do kterých se umístí jednotlivé parametry. Bohužel popis parametrů, který se v Excelu uvádí, není vždy úplně intuitivní. Proto jsou zde uvedeny i dva sloupce, kde jsou zapsány názvy parametrů z Excelu a jim odpovídají pořadí parametrů, které již známe z oblasti pravděpodobnosti.
Poslední parametr u funkcí, které počítají v MS Excelu pravděpodobnostní rozdělení, rozhoduje o tom, zda jde o výpočet pravděpodobnostní funkce (zapíše se číslo 0) nebo distribuční funkce (zapíše se číslo 1) v daném bodě.
Výpočet, který chceme provést | Parametry funkce | Funkce v MS Excelu | Označení parametrů funkce v MS Excelu |
Exponenciální rozdělení | (x;
) | EXPON.DIST | (x; lambda; kumulativní) |
Normální rozdělení | (x; μ; σ2) | NORM.DIST | (x; střed_hodn; sm_odch; kumulativní) |
Logaritmicko-normální rozdělení | (x; μ; σ2) | LOGNORM.DIST | (x; střední; sm_odchylka; kumulativní) |
Chí-kvadrát rozdělení | (
) | CHISQ.DIST | (x; volnost; kumulativní) |
Rozdělení t | (x;
t) | T.DIST T.DIST.2T T.DIST.RT | (x; volnost; kumulativní) (x; volnost) (x; volnost) |
Rozděleni F |
;
) | F.DIST | (x; volnost; volnost; kumulativní) |
V případě, že potřebujete vypočítat kvantily těchto rozdělení, zpravidla je začátek funkce v MS Excel stejný, ale místo „DIST“ je použita koncovka „INV“.
Výpočet, který chceme provést | Parametry funkce | Funkce v MS Excelu | Označení parametrů funkce v MS Excelu |
Kvantily normálního rozdělení | (p; μ; σ2) | NORM.INV | (pravděpodobnost; střední; sm_odch) |
Kvantily logaritmicko-normálního rozdělení | (p; μ; σ2) | LOGNORM.INV | (pravděpodobnost; stř_hodn; sm_odch) |
Kvantily chí-kvadrát rozdělení | (
) | CHISQ.INV | (pravděpodobnost; volnost) |
Kvantily rozdělení t | (
t) | T.INV T.INV.2T | (pravděpodobnost; volnost) (pravděpodobnost; volnost) |
Kvantily rozděleni F |
;
) | F.INV | (pravděpodobnost; volnost; volnost) |