4.1
Konceptuální modelování
Konceptuální model (velmi často je také označován jako E-R model) je množina pojmů, které nám pomáhají, na konceptuální úrovni abstrakce, popsat realitu za účelem následně specifikovat strukturu databáze. Je potřeba si uvědomit, že konceptuální úrovní abstrakce myslíme to, že v popředí zájmu je pouze modelovaná realita. Na této úrovni se ještě nestaráme o to, jak bude budoucí databáze technicky spravována a řízena. Neřešíme tedy, o jakou databázový model se bude jednat – relační, objektový, a podobně.
Pokud chceme vytvořit integritní a konzistentní databázi, je zapotřebí věnovat velkou pozornost návrhu samotné databáze. Je potřeba se zaměřit na tři fáze návrhu:
- Analýza požadavků.
- Datové modelování.
- Normalizace.
V první řade je zapotřebí, seznámit se se základními pojmy, aby bylo možné správně databázi navrhnout.
4.1.1
Entita a atribut
Entitou rozumíme libovolnou existující osobu, zvíře, věc či jev (obecně objekt) reálného světa. Entita musí být rozlišitelná od ostatních entit a existovat nezávisle na nich.
+

Obr. 11. Entita
Při práci s entitami a jejich dekompozicí se může stát, že vytvoříme entity, které jsou nesmyslné, ale jsou v závislosti na jiném entitním typu. Tak se nám může stát, že vytvoříme položku „Vypujcka“, ale ta má vztah ke knize, kterou si vypůjčíme. V ostatních případech je tato položka zbytečná.
Můžeme ale přemýšlet i jiným způsobem. V rámci konceptualizace se zamyslíme nad tím, jaké pojmy v daném prostředí lidé používají a jakým pojmům rozumí. To znamená, že vůbec nevytvoříme entitní typy. Položka „Vypujcka“ je jistě pojmem, o kterém jasně víme, k čemu slouží. Je nám naprosto jasné, že s touto položkou musíme v databázi počítat a rozumíme tomu, s jakými dalšími položkami se tato položka pojí. A právě tento přístup nám dává představu o tom, jak chápat tyto slabé pojmy jako entitu.
V databázi se tyto entitní typy nazývají slabé entitní typy. V databázi se dají poznat velice jednoduše. V rámci takové entity totiž není možné, aby z atributů byl složen identifikátor těchto entit. Je zapotřebí, aby k identifikaci takové entity byla k dispozici entita nebo entity, s nimiž se tyto entity spojují. Například k identifikaci položky „Vypujcka“ musíme nezbytně vědět, ke které knize patří. Jinak ji nelze jednoznačně identifikovat. Pokud se zaměříme na vztah tohoto slabého entitního typu k jiné entitě, můžeme konstatovat, že tento vztah je nositelem identifikační závislosti.
Abychom chápali celý model správně, je velice důležité nalézt a použít výstižné názvy entit. Je pravda, že s tím je spojeno dost problémů. Jedním z těchto problémů může být fakt, že název, který jsme zvolili, má jiný význam pro nějakou oblast, je obecný a podobně. Je tedy vhodné doplnit k jednotlivým názvům popisky, popřípadě uvedeme konkrétní příklady.
Vezměme si učitele na nějaké vyšší odborné škole nebo na vysoké škole. V rámci pracovně právního vztahu tu pracují interní zaměstnanci (na smlouvu) anebo externí zaměstnanci (na dohodu o provedení práce). Dále tu pracují zaměstnanci, kteří jsou provozními pracovníky a mohou vyučovat na zkrácený úvazek odborné předměty nebo provádějí školení.
Různí uživatelé mohou pro stejný entitní typ používat různé názvy. Například "učitelům" někteří administrativní pracovníci vyšší školy nebo vysoké školy mohou říkat "pedagogové". Analýza má podchytit, jak uživatelé v dané oblasti zájmu entitám říkají – pokud jim různí uživatelé říkají různě, je potřeba tuto skutečnost respektovat. Potom pro název nějakého entitního typu máme synonyma. Je však třeba dát pozor, aby se jednalo o skutečně stejný význam, protože častější jsou případy, kdy jde sice o významy překrývající se, ale ne úplně shodné.
Atribut je funkce přiřazující entitám či vztahům hodnotu (zde popisného typu), která určuje některou podstatnou vlastnost entity nebo vztahu. Atribut je tedy vlastnost entity, která jí blíže charakterizuje.
+
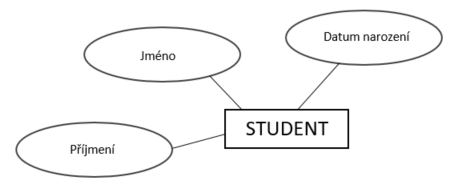
Obr. 12. Atribut
Rozlišujeme tyto atributy:
- podle volitelnosti – atribut má hodnotu pro každý výskyt entity (totální atribut) nebo nemusí mít hodnotu pro každý výskyt entity (parciální atribut);
- podle odvoditelnosti – atribut nelze odvodit z jiných atributů (základní atribut) nebo lze atribut získat odvozením z jiných atributů (odvoditelný atribut).
4.1.2
Klíče
Klíč je minimální množina atributů, zajišťující jednoznačnou identifikaci výskytů entity, je tedy identifikátorem entity. Tento klíč je nazýván primárním klíčem. Na primární klíč je kladeno několik podmínek, které by měl splňovat.
Primární klíč by měl být:
- jednoznačný – jedna hodnota identifikátoru určuje právě jeden výskyt entity;
- úplný – pro každý výskyt entity existuje právě jedna hodnota identifikátoru;
- minimální – v případě, že je identifikátor složený z více atributů, pak nesmí obsahovat žádnou podmnožinu, která je jednoznačná a úplná;
- stabilní – během života entity nemění svojí hodnotu.
V relačních databázích rozlišujeme následující typy klíčů:
- kandidátní klíč – klíč, který je kandidátem na identifikační klíč, nemusí se jím ale stát;
- cizí klíč – atribut, který je v jiné entitě identifikačním klíčem nebo jeho částí;
- alternativní klíč – minimální množina atributů zajišťující jednoznačnou identifikaci výskytů entity, která nebyla zvolena za identifikační klíč;
- sekundární klíč – neprázdná množina atributů, které jsou důležité pro přístup k datům reprezentovaným entitou.
Kandidátní klíč v relačním modelování označuje sloupec nebo kombinaci sloupců, ve kterých mají všechny řádky tabulky své hodnoty unikátní.
Cizí klíč slouží k propojení tabulek. Jedná se o sloupec, nebo množinu sloupců, která umožní identifikovat záznamy z různých tabulek, jenž spolu navzájem souvisí. Funguje jako křížový odkaz mezi tabulkami, protože odkazuje na primární klíč jiné tabulky, čímž vytváří vazbu mezi nimi.
Alternativní klíč slouží v relačních databázích jako alternativa k primárnímu klíči. Jedná se o jedinečný identifikátor pro každou instanci entity, stejně tak jako to je u primárního klíče.