7.2
Modely organizace dat v relačních databázových systémech
Pro návrh datových struktur souborů slouží datové modely. Jejich tvorba nezávisí na fyzickém uložení v paměti počítače a na operačním prostředí. Nejčastěji se používá entitně - relační model.
Definice
Entitně - relační model (ERD) stanoví pravidla pro uspořádání dat do relací (dvourozměrných tabulek).
Tento model obsahuje grafické znázornění entit a jejich vzájemných vazeb. Je sestavený jako statický model systému. Základními vlastnostmi jsou:
- slouží pro analýzu vazeb mezi entitami;
- je vhodný pro sestavování množiny struktur přímo v minimalizované podobě;
- poskytuje podklad pro návrh fyzické struktury souborů s SW relačního databázového systému.
Grafická část modelu se sestavuje ze dvou základních komponent:
Datová entita - reprezentuje tabulku dat v RDS. Entitu tvoří skupina datových prvků (položek), charakterizující tento objekt. Z pohledu databáze entita představuje strukturu položek tabulky. Název je tvořen podstatným jménem v jednotném čísle. Entita musí splňovat podmínky:
- každá entita musí obsahovat jeden nebo více datových prvků.
- entita musí být obsažena v popisovaném informačním systému.
Relační vazby - představují logické vztahy mezi entitami, která se vyjadřuje slovesem. Důležité i stanovení typu vazby - kardinality.
Kardinalita popisuje vztah mezi výskyty záznamů svázaných entit. Může být následující:
N:M | N výskytů záznamů v první entitě je svázáno s M výskyty záznamů ve druhé entitě |
1:M | jeden výskyt záznamu v první entitě je svázán s M výskyty záznamů ve druhé entitě |
M:1 | M výskytů záznamů v první entitě je svázáno s jedním výskytem záznamu ve druhé entitě |
1:1 | jeden výskyt záznamu v první entitě je svázán s jedním výskytem záznamu v entitě druhé |
+
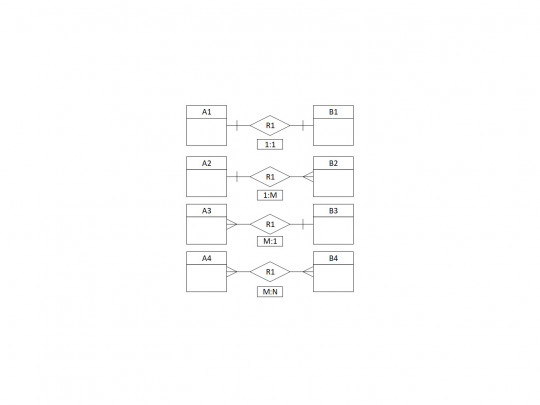
Obr. 26. Grafické znázornění kardinality vztahů mezi entitami.
Algoritmus tvorby ERD modelu můžeme rozdělit do sedmi základních kroků.
První krok:
Ze seznamu všech datových prvků se vytvoří tří základní skupiny podle vlastností:
1. skupina - obsahuje pouze datová prvky s charakterem determinantu.
2. skupina - obsahuje prvky, jejichž hodnoty jsou jednoznačně určeny determinanty z prvků 1. skupiny.
3. skupina - ostatní prvky, nezařazené do předchozích skupin.
Jména prvků se mohou ve všech skupinách vyskytovat pouze jednou.
Druhý krok:
Provádí se reorganizace 3. skupiny datových prvků. Prověřuje se možnost determinovat prvek pomocí složeného determinantu z prvků 1. skupiny. Nemá-li prvek takovouto možnost, přeřadí se do 1. skupiny a tvoří determinant sám sobě.
Třetí krok:
Datové položky roztříděné v kroku 2 se spojí do spolu souvisejících entit a subtypů a přiřadí se jim vhodné názvy.
Čtvrtý krok:
Nyní se sestaví předběžný entitně-relační diagram, která obsahuje pouze jednotlivé entity a určí se kardinalita jednotlivých relačních vazeb. Jako nejčastější otázkou při stanovení kardinality je:
"Kolik záznamů v cílové entitě může náležet k jednomu záznamu ve výchozí entitě."
Pátý krok:
Do předběžného ERD se doplní značky vazeb s výstižným slovesným pojmenováním.
Šestý krok:
ERD představuje pouze grafické znázornění modelu. Pro další použití je nutné definovat logické struktury jednotlivých entit a navrhnou relační vazby.
Sedmý krok:
Tento poslední krok představuje normalizaci navržených struktur v závislosti na zajištění funkce relačních vazeb. Při normalizaci používáme následující pravidla (podle [22]):
Je-li kardinalita 1:1, vloží se determinant jedné entity do struktury druhé entity. Toto rozšíření se provede u obou entit.
Je-li kardinalita 1:M vloží se primární klíč entity s kardinalitou 1 do logické struktury s kardinalitou M.
Je-li kardinalita M:N můžeme říci, že jsou struktury normalizované, prakticky to však znamená, že tuto vazbu musíme převést přes další entitu, která bude obsahovat determinant složený s determinantů obou entit.
Zrušíme ty struktury, které obsahují pouze jeden prvek, protože zákonitě musí existovat i v jiné struktuře.